
Idee
Die -Verteilung wird insbesondere für Hypothesentests und Konfidenzintervalle benötigt. In beiden Situationen interessiert uns nämlich die Verteilung des Stichprobenmittelwerts.
Und falls die wahre Varianz der Daten nicht bekannt ist, d.h. man stattdessen die Stichprobenvarianz berechnen muss (und das ist in der Realität quasi immer so), ist der Mittelwert der Stichprobe nämlich nicht normalverteilt, sondern -verteilt mit Freiheitsgraden.
Klausuraufgaben

Im eBook-Shop gibt es Klausuraufgaben zu diesem Thema!
Zu den eBooks
Wenn ich also aus einer großen Grundgesamtheit (mit Mittelwert 0) für 365 Tage lang jeden Tag eine Stichprobe der Größe ziehe, und dann den Mittelwert daraus bilde, folgen die so bestimmten 365 Mittelwerte einer -Verteilung mit Freiheitsgraden. Das Histogramm dieser 365 Datenpunkte läge also sehr nah an dieser theoretischen -Verteilung der Daten.
Es gilt dann:
Die Standardisierung, d.h. das Subtrahieren von und das Teilen durch , geschieht aus dem Grund, dass die danach erhaltenen Zahlen auf einer einheitlichen Skala leben (man kann sagen: von etwa -3 bis +3), und man dann nur eine einzige Tabelle drucken muss. Wenn man zum Beispiel mit einem Hypothesentest überprüfen möchte, ob die durchschnittliche Körpergrösse bei Männern 175cm ist, dann setzt man . Vom tatsächlichen durchschnittlichen Wert der Stichprobe (z.B. 176.3cm) zieht man nun die postulierten 175cm (also ) ab, und teilt durch die berechnete Standardabweichung aus der Stichprobe.
Als kurze Anmerkung sei erwähnt, dass für größere Stichproben (Faustregeln sprechen oft von oder ) statt der -Verteilung als Approximation auch die Normalverteilung verwendet werden kann. Die Kurven der Dichte und Verteilungsfunktion der Normalverteilung und -Verteilung mit sehr vielen Freiheitsgraden sind nämlich ähnlich genug, dass es fast keinen Unterschied macht, welche man verwendet.
Parameter
Je größer die Stichprobe wird, desto größer wird die Anzahl der Freiheitsgrade, und desto mehr ähnelt die zugehörige -Verteilung dann der Normalverteilung. Die folgende Grafik veranschaulicht den Einfluss des Parameters :
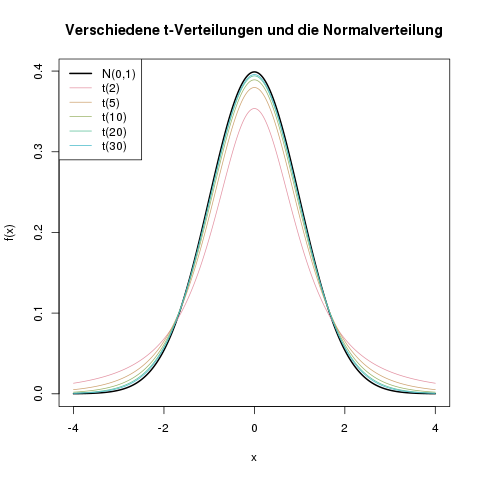
Die -Verteilung hat eine breitere Streuung als die Standardnormalverteilung . Mit steigender Anzahl der Freiheitsgrade nähert sich die -Verteilung aber der Normalverteilungskurve an. Ab etwa ist sie nah genug an der Normalverteilung, dass man die -Verteilung mit ihr approximieren kann.
Je höher also die Anzahl der Freiheitsgrade , desto ähnlicher ist die -Verteilung der Standardnormalverteilung . Ab etwa 50 Freiheitsgraden, also , kann man mit dem Auge fast keinen Unterschied mehr zwischen den beiden Kurven erkennen.
Für eine -verteilte Zufallsvariable mit Freiheitsgraden schreibt man
Träger
Die -Verteilung geht genauso wie die Normalverteilung über die gesamten reellen Zahlen. Ihr Träger ist also
Erwartungswert, Varianz und Dichte
Man benötigt in der Praxis eigentlich nur die Verteilungsfunktion der -Verteilung, wie vorher schon erwähnt, um Hypothesentests und Konfidenzintervalle rechnen zu können. Es wird also in der Statistik (und in Klausuren) in den allermeisten Fällen weder die Dichtefunktion, noch Erwartungswert und Varianz vorkommen.
Der Vollständigkeit halber sei aber erwähnt, dass für eine -verteilte Zufallsvariable der Erwartungswert , und die Varianz ist.
Verteilungsfunktion
Die Verteilungsfunktion (genauso wie die Dichtefunktion) lässt sich nur sehr eklig als Formel notieren. Das Ausrechnen dieser Funktion ist wohl niemandem zuzumuten, weshalb es für die -Verteilung auch eine Verteilungstabelle gibt, in der man die wichtigsten Werte nachschlagen kann.
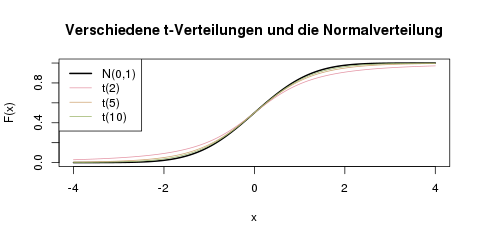
Verteilungsfunktionen für drei ausgewählte -Verteilungen. Auch die Verteilungsfunktion ähnelt sich mit steigenden Freiheitsgraden immer mehr der Standardnormalverteilung an.

Hey, gute Erklärungen. Bin grad am lernen für Statistik. Hatte die Formel vor mir ( Mittelw. X – Erwartungswert/Populationsmittelw. / Varianz d. Stichprobenvert).
Ich verstand aber nicht ganz warum man Mittelw. X minus Erwartungswert rechnet. Warum ist Erwartungswert in diesem Fall = 0? Mein Erwartungswert hat in den Beispielen bis jetzt meist demm Mittelwert entsprochen. Ist es ein resultat der z-Standardisierung?
Danke im Vorraus
Die Standardisierung, d.h. das Subtrahieren von
Ist das so verständlich? Ich habe den Artikel um diesen Paragraphen ergänzt.
VG
Alex
Woher weiß ich wie viel Freiheitsgradedie Verteilung hat?
Wirklich tolle Beiträge =)
Endlich sind die einzelnen Themen mal verständlich erklärt und mit guten Beispielen.
Wenn ich richtig gesehen habe, hast du zur F-Verteilung noch nichts oder?
Werde mich mal weiter durchscrollen und mein Statistikverständnis vertiefen 😉
Hallo …
Einfach Klasse die Zusammenstellung des ebooks und der Aufgabe t-Verteilung