In den bisherigen Artikeln zur Regression ging es nur um die einfache lineare Regression. Hier schauen wir uns nun die multiple lineare Regression an.
Das Wort „multipel“ bedeutet, dass wir nun nicht mehr eine, sondern mehrere Einflussgrößen haben. Wichtig: es gibt mehrere Einflussgrößen. Die Anzahl der Zielgrößen verändert sich nicht, es ist immer noch nur eine Zielgröße.
 Im eBook-Shop gibt es Klausuraufgaben zu diesem Thema!
Im eBook-Shop gibt es Klausuraufgaben zu diesem Thema!Beispiel
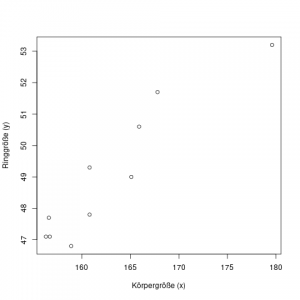
Wir können uns das Beispiel aus den Artikeln zur einfachen linearen Regression ansehen, und es etwas weiterführen. Dort haben wir versucht, mit Hilfe der Regression die Ringgröße \(y\) einer Freundin zu schätzen, gegeben man kennt ihre Körpergröße \(x\).
Wenn dir jetzt allerdings sehr viel daran liegt, eine möglicht exakte Schätzung zu erhalten, um nicht mit einem unpassenden Ring vor ihr zu stehen, kannst du noch mehr Daten sammeln. Beispielsweise zusätzlich zur Körpergröße noch das Gewicht und das Alter von den 10 Frauen, die du befragst.
Die Daten würden nun also um zwei Variablen größer werden, und zum Beispiel so aussehen:
| Person \(i\) | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| Körpergröße \(x_1\) | 156.3 | 158.9 | 160.8 | 179.6 | 156.6 | 165.1 | 165.9 | 156.7 | 167.8 | 160.8 |
| Körpergewicht \(x_2\) | 62 | 52 | 83 | 69 | 74 | 52 | 77 | 65 | 79 | 51 |
| Alter \(x_3\) | 24 | 34 | 26 | 51 | 43 | 33 | 22 | 21 | 19 | 34 |
| Ringgröße \(y\) | 47.1 | 46.8 | 49.3 | 53.2 | 47.7 | 49.0 | 50.6 | 47.1 | 51.7 | 47.8 |
Wir haben jetzt nicht mehr eine Einflussgröße \(x\), sondern drei Stück: \(x_1\), \(x_2\), und \(x_3\). Und jede dieser Einflussgrößen hat eine Ausprägung pro Person \(i\). Das heißt, dass nun zwei Zahlen unter dem \(x\) stehen: Eine für die Einflussgröße und eine für die Person. Zum Beispiel ist das Körpergewicht der vierten Person \(x_{2,4} = 69kg\).
Dadurch, dass man jetzt mehr Daten verfügbar hat, kann man eine genauere Schätzung bekommen. Die Regressionsgleichung würde jetzt lauten:
\[ y = a + b_1 x_1 + b_2 x_2 + b_3 x_3 \]
Mit der multiplen Regression kann ich nun Werte für die Parameter \(a\), \(b_1\), \(b_2\), und \(b_3\) erhalten, und mit Hilfe derer kann ich nun wieder eine Vorhersage treffen.
Anmerkung: Genauso wie in der einfachen linearen Regression können die Parameter in anderen Büchern/Skripten anders benannt sein (z.B. \(\beta_0\), \(\beta_1\) usw.). Sie bedeuten aber genau dasselbe.
Schätzung der Parameter
Die Parameterschätzung ist etwas aufwändiger, und von Hand praktisch nicht mehr durchführbar. Grob gesagt werden die drei Einflussgrößen \(x_1\), \(x_2\) und \(x_3\), die man ja als Vektoren ansehen kann, spaltenweise in eine Matrix \(X\) zusammengefasst. Mit Hilfe dieser Matrix und dem Vektor aller Zielgrößen \(y\) kann man dann den Vektor der Parameter (nennen wir ihn mal \(b\)) schätzen:
\[ b = (X^\top X)^{-1} X^\top y \]
Das wird, wie gesagt, etwas komplizierter, und ist auch mit dem Taschenrechner nicht mehr zu lösen. In einer Klausur wird das Berechnen der Parameter in einer multiplen Regression nicht abgefragt werden, weshalb ich die Details hier überspringe. Die Standardliteratur hilft hier aber weiter (ich empfehle die Springer-Bücher zur Regression oder Statistik).
Was aber durchaus Klausurstoff sein kann, ist die Interpretation der Parameter und die Vorhersage mit bereits gegebenen Parametern. Das schauen wir uns jetzt noch genauer an.
Interpretation der Parameter
Wie gesagt, die Berechnung bei der multiplen Regression ist zu kompliziert für Papier und Taschenrechner, daher lasse ich die Herleitung hier weg. Aber mit den Daten aus der obigen Tabelle erhalten wir per Computer gerundet die folgenden Parameter:
\(a=0.6\), \(b_1=0.28\), \(b_2=0.06\), und \(b_3=-0.02\).
Die Regressionsgerade sieht also so aus:
\[ y = 0.66 + 0.28 \cdot x_1 + 0.06 \cdot x_2 – 0.02 \cdot x_3 \]
Was bedeuten diese Parameter nun?
Der Wert \(b_1\), also 0.28, sagt aus, dass bei einer Person, die einen Zentimeter größer ist als eine andere, die Ringgröße im Durchschnitt um 0.28 größer ist. Da der Wert 0.28 größer als Null ist, sprechen wir hier von einem positiven Effekt: Eine größere Körpergröße führt zu einer größeren Ringgröße.
Andersherum ist es beim Alter. Der Wert von -0.02 sagt aus, dass eine Person, die ein Jahr älter ist, im Durchschnitt eine um 0.02 kleinere Ringgröße hat. Das ist ein negativer Effekt, denn der Wert \(b_3\) ist kleiner als Null.
Da wir bei einer Stichprobe aber immer mit zufälligen Daten arbeiten, ist der Parameter für quasi jede Einflussgröße nie exakt Null. Der Parameter für das Alter, die -0.02, sind z.B. so klein, dass sie eventuell schon zufällig auftreten. Die Vermutung liegt nahe, dass das Alter gar keinen Einfluss auf die Ringgröße hat (aber das Gewicht und die Körpergröße durchaus).
Um zu prüfen, ob eine Einflussgröße tatsächlich einen Einfluss hat, gibt statistische Software normalerweise einen \(p\)-Wert zusätzlich zu dem Parameterschätzer aus. Dieser \(p\)-Wert gehört zu der Hypothese, dass der jeweilige Effekt (z.B. vom Alter) gleich Null ist. Wenn der \(p\)-Wert klein genug ist (meist: kleiner als 0.05), dann geht man davon aus, dass die zugehörige Einflussgröße tatsächlich einen Effekt auf die Zielgröße hat, und man spricht von einem signifikanten Effekt.
In unserem Beispiel sind die \(p\)-Werte:
– Für \(b_1\) (Körpergröße): \(p=0.0000026\)
– Für \(b_2\) (Gewicht): \(p=0.00099\)
– Für \(b_3\) (Alter): \(p=0.112\)
Da nur die ersten beiden \(p\)-Werte kleiner als 0.05 sind, können wir hier schlußfolgern, dass sowohl die Körpergröße, als auch das Gewicht einen signifikanten Einfluss auf die Ringgröße haben, aber das Alter nicht.
(Das Berechnen der \(p\)-Werte ist wieder etwas komplizierter, und in einer Klausur wohl nicht gefragt werden, und wird daher hier übersprungen. Falls das jemand genauer wissen will, verweise ich wieder auf die Standardliteratur zur Regression.)
Vorhersage bei der multiplen linearen Regression
Bei der multiplen linearen Regression läuft die Vorhersage genauso ab wie bei der einfachen Regression, nur eben mit mehreren Einflussgrößen. Unsere Regressionsgleichung lautet:
\[ y = 0.66 + 0.28 \cdot x_1 + 0.06 \cdot x_2 – 0.02 \cdot x_3 \]
Das heißt, wenn unsere Freundin nun wie bisher 170cm groß ist, aber wir zusätzlich wissen, dass sie 68kg wiegt und 29 Jahre alt ist, dann können wir eine genauere Schätzung für die Ringgröße abgeben:
\[y = 0.66 + 0.28 \cdot 170 + 0.06 \cdot 68 – 0.02 \cdot 29 = 51.76 \]
Wir erwarten also in etwa eine Ringgröße von 51.76, und sollten daher einen Ring mit einer Größe kaufen, der so nah wie möglich daran liegt (also wahrscheinlich einen der Größe 52).
 Im eBook-Shop gibt es Klausuraufgaben zu diesem Thema!
Im eBook-Shop gibt es Klausuraufgaben zu diesem Thema!